Rangkuman Pertemuan 22 mengenai Natural Language Processing :
1. Text Classification
Text Classification atau Text Categorization adalah suatu proses pengelompokan dokumen, yang dalam tugas akhir ini adalah konten web page, ke dalam beberapa kelas yang telah ditentukan. Jika tidak ada overlap antar kelas, yaitu setiap dokumen hanya dikelompokan kedalam satu kelas maka text categorization ini disebut single label text categorization . Text categorization bertujuan untuk menemukan model dalam mengkategorisasikan teks natural language. Model tersebut akan digunakan untuk menentukan kelas dari suatu dokumen.
Beberapa metode text categorization yang sering dipakai antara lain : k- Nearest Neighbor, Naïve Bayes, Support Vektor Machine, Decision Tree, Neural Networks, Boosting.
Dalam pengaplikasian text categorization terdapat beberapa tahap, yaitu :
>>Preprocessing
Tahap pertama dalam text categorization adalah dokumen preprocessing adalah :
1. Ekstrasi Term
Ekstrasi term dilakukan untuk menentukan kumpulan term yang mendeskripsikan dokumen. Kumpulan dokumen di parsing untuk menghasilkan daftar term yang ada pada seluruh dokumen. Daftar term yang dihasilkan disaring dengan membuang tanda baca, angka, simbol dan stopwords. Dalam tugas akhir ini akan dibahas juga mengenai pengaruh stopwords removal terhadap hasil klasifikasi. Berikut ini merupakan penjelasan singkat mengenai stopwords.
Kebanyakan bahasa resmi di berbagai negara memiliki kata fungsi dan kata sambung seperti artikel dan preposisi yang hampir selalu muncul pada dokumen teks. Biasanya kata-kata ini tidak memiliki arti yang lebih di dalam memenuhi kebutuhan seorang searcher di dalam mencari informasi. Kata-kata tersebut (misalnya a, an, dan on pada bahasa Inggris) disebut sebagai Stopwords.
Sebuah sistem Text Retrieval biasanya disertai dengan sebuah Stoplist. Stoplist berisi sekumpulan kata yang ‘tidak relevan’, namun sering sekali muncul dalam sebuah dokumen. Dengan kata lain Stoplist berisi sekumpulan Stopwords.
Stopwords removal adalah sebuah proses untuk menghilangkan kata yang ‘tidak relevan’ pada hasil parsing sebuah dokumen teks dengan cara membandingkannya dengan Stoplist yang ada.
2. Seleksi Term
Jumlah term yang dihasilkan pada feature ekstrasi dapat menjadi suatu data yang berdimensi cukup besar. Karena dimensi dari ruang feature merupakan bag-of-words hasil pemisahan kata dari dokumennya. Untuk itu perlu dilakukan feature selection untuk mengurangi jumlah dimensi.
3. Representasi Dokumen
Supaya teks natural language dapat digunakan sebagai inputan untuk metode klasifikasi maka teks natural language diubah kedalam representasi vektor. Dokumen direpresentasikan sebagai vektor dari bobot term, dimana setiap term menggambarkan informasi khusus tentang suatu dokumen. Pembobotan dilakukan dengan melakukan perhitungan TFIDF. Term beserta bobotnya kemudian disusun dalam bentuk matrik.
>>Training Phase
Tahap kedua dari text categorization adalah training. Pada tahap ini system akan membangun model yang berfungsi untuk menentukan kelas dari dokumen yang belum diketahui kelasnya. Tahap ini menggunakan data yang telah diketahui kelasnya (data training) yang kemudian akan dibentuk model yang direpresantasikan melalui data statistik berupa mean dan standar deviasi masing-masing term pada setiap kelas.
>>Testing Phase
Tahap terakhir adalah tahap pengujian yang akan memberikan kelas pada data testing dengan menggunakan model yang telah dibangun pada tahap training. Tujuan dilakukan testing adalah untuk mengetahui performansi dari model yang telah dibentuk. Dengan beberapa parameter pengukuran yaitu akurasi, precision, recall, dan f-measure.
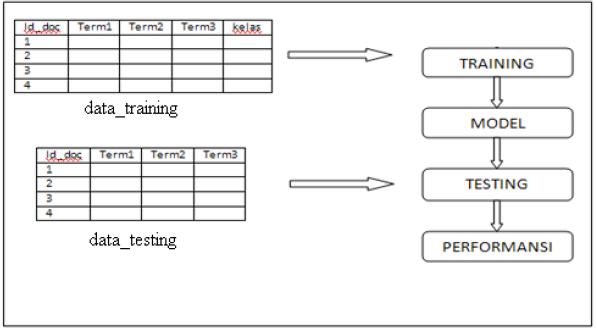
2. Information Retrieval
Information Retrieval digunakan untuk menemukan kembali informasi-informasi yang relevan terhadap kebutuhan pengguna dari suatu kumpulan informasi secara otomatis. Salah satu aplikasi umum dari sistem temu kembali informasi adalah search-engine atau mesin pencarian yang terdapat pada jaringan internet. Pengguna dapat mencari halaman-halaman Web yang dibutuhkannya melalui mesin tersebut.
Ukuran efektifitas pencarian ditentukan oleh precision dan recall. Precision adalah rasio jumlah dokumen relevan yang ditemukan dengan total jumlah dokumen yang ditemukan oleh search-engine. Precision mengindikasikan kualitas himpunan jawaban, tetapi tidak memandang total jumlah dokumen yang relevan dalam kumpulan dokumen.
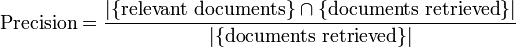
Recall adalah rasio jumlah dokumen relevan yang ditemukan kembali dengan total jumlah dokumen dalam kumpulan dokumen yang dianggap relevan.
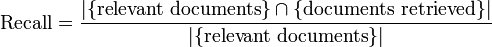
Dalam Information Retrieval, mendapatkan dokumen yang relevan tidaklah cukup. Tujuan yang harus dipenuhi adalah bagaimana mendapatkan doukmen relevan dan tidak mendapatkan dokumen yang tidak relevan. Tujuan lainnya adalah bagaimana menyusun dokumen yang telah didapatkan tersebut ditampilkan terurut dari dokumen yang memiliki tingkat relevansi lebih tingi ke tingkat relevansi rendah. Penyusunan dokumen terurut tersebut disebut sebagai perangkingan dokumen. Model Ruang Vektor dan Model Probabilistik adalah 2 model pendekatan untuk melakukan hal tersebut.
Model ruang vektor dan model probabilistik adalah model yang menggunakan pembobotan kata dan perangkingan dokumen. Hasil retrieval yang didapat dari model-model ini adalah dokumen terangking yang dianggap paling relevan terhadap query.
Dalam model ruang vektor, dokumen dan query direpresentasikan sebagai vektor dalam dalam ruang vektor yang disusun dalam indeks term, kemudian dimodelkan dengan persamaan geometri. Sedangkan model probabilistik membuat asumsi-asumsi distribusi term dalam dokumen relevan dan tidak relevan dalam orde estimasi kemungkinan relevansi suatu dokumen terhadap suatu query.
3. HITS Algorithm
Hyperlink-Induced Topic Search (HITS) adalah sebuah algoritma analisis link halaman Web, yang merupakan pendahulu dari PageRank. Ide di balik Dengan kata lain, sebuah hub baik mewakili halaman yang menunjuk ke halaman lain, dan otoritas yang baik mewakili halaman yang dihubungkan oleh banyak hub berbeda.
Algoritma ini melakukan serangkaian iterasi, masing-masing terdiri dari dua langkah dasar, yaitu :
- Authority Update :
Memperbarui skor Authority setiap node untuk menjadi sama dengan jumlah dari Hub Skor dari setiap node yang menunjuk ke itu. Artinya, node diberi skor otoritas tinggi dengan menjadi terhubung ke halaman yang dikenali sebagai hub untuk informasi.
- Hub Update :
Memperbarui setiap node Hub Skor menjadi sama dengan jumlah dari Otoritas Skor dari setiap node yang menunjuk ke. Artinya, node diberi skor tinggi hub dengan menghubungkan ke node yang dianggap otoritas pada subjek.
Algoritma Hyperlink Induced Topic Search (HITS) Kleinberg memberikan gagasan baru tentang hubungan antara hubs dan authorities. Dalam algoritma HITS, setiap simpul (situs) p diberi bobot hub (xp) dan bobot authority (yp).
Pada akhirnya, algoritma HITS ini menghasilkan sebuah daftar singkat yang terdiri dari situs-situs dengan bobot hub terbesar serta situs-situs dengan bobot authority terbesar. Yang menarik dari algoritma HITS adalah: setelah memanfaatkan kata kunci (topik yang dicari) untuk membuat himpunan akar (root) R, algoritma ini selanjutnya sama sekali tidak mempedulikan isi tekstual dari situs-situs hasil pencarian tersebut.
Dengan kata lain, HITS murni merupakan sebuah algoritma berbasis link setelah himpunan akar terbentuk. Walaupun demikian, secara mengejutkan HITS memberikan hasil pencarian yang baik untuk banyak kata kunci.
Sebagai contoh, ketika dites dengan kata kunci “search engine”, lima authorities terbaik yang dihasilkan oleh algoritma HITS adalah Yahoo!, Lycos, AltaVista, Magellan, dan Excite – padahal tidak satupun dari situs-situ tersebut mengandung kata “search engine”.
4. Prolog
Prolog adalah singkatan daripada PROgramming in LOGic. Prolog merupakan satu ide yang dicetuskan pada awal 1970an untuk menggunakan logika sebagai bahasa pemprograman. Mereka yang bertanggungjawab dalam pengembangan ide ini ialah Robert Kowalski dari Edinburgh dalam aspek teori dan Colmerauer dari Marseilles dalam aspek implementasi.
Prolog biasanya dikaitkan dengan berlogika dan merupakan bahasa pemprograman untuk perhitungan simbolik dan tak-berangka. Prolog paling sesuai untuk menyelesaikan masalah yang berkaitan dengan objek dan hubungan antara objek, masalah persamaan corak, masalah penjejakan ke belakang dan masalah yang informasinya tidak lengkap.
Algoritma dalam Prolog terdiri dari logika dan kontrol. Logika merupakan fakta dan peraturan yang menerangkan apa yang seharusnya dilakukan oleh algoritma. Sedangkan kontrol merupakan cara algoritma bisa Munir: Pengenalan Bahasa Prolog 2
diimplementasikan dengan menggunakan peraturan. Sintaks yang dibentuk dalam Prolog adalah dalam bentuk klausa atau formula First Order Predicate Logic.
Prolog adalah bahasa pemrograman logika atau di sebut juga sebagai bahasa non-procedural. Namanya diambil dari bahasa Perancis programmation en logique (pemrograman logika). Bahasa ini diciptakan oleh Alain Colmerauer dan Robert Kowalski sekitar tahun 1972 dalam upaya untuk menciptakan suatu bahasa pemrograman yang memungkinkan pernyataan logika alih-alih rangkaian perintah untuk dijalankan komputer.
Berbeda dengan bahasa pemrograman yang lain, yang menggunakan algoritma konvensional sebagai teknik pencariannya seperti pada Delphi, Pascal, BASIC, COBOL danbahasa pemrograman yang sejenisnya, maka prolog menggunakan teknik pencarian yang di sebut heuristik (heutistic) dengan menggunakan pohon logika.